Understanding Quantisation in Large Language Models (LLMs)

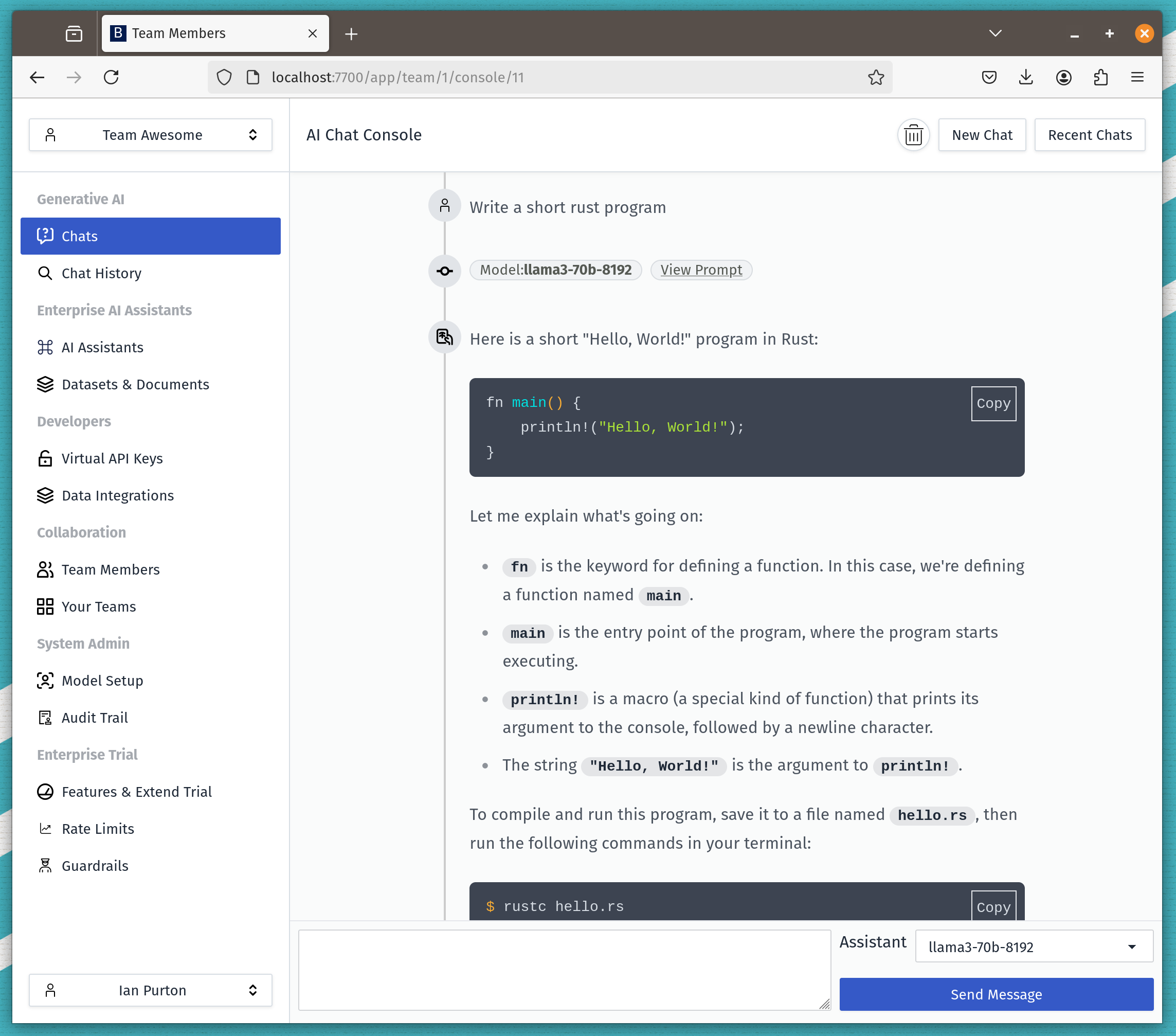
The default setup for Bionic allows you to run a proof of concept on your laptop, but given the much publicised large resource requirements for LLMs how do we achieve this. Step forward quantisation.
What is Quantisation?
Quantisation, in the context of LLMs, is a process of simplifying the way these models store and work with data. Instead of dealing with a vast range of numbers and values, quantisation reduces them to a limited set of discrete values or levels. Think about compressing a jpeg photograph, you can still see what it his but some of the finer details have been lost
Why Do We Need Quantisation in LLMs?
- Efficient Storage and Computation: LLMs are massive networks with billions of parameters. Quantisation makes it easier to store and work with these models, reducing the memory and computational resources required. This efficiency is essential for running these models on various devices, from supercomputers to your smartphone.
- Faster Inference: When you ask a question to an LLM, it needs to process your query quickly and provide a response. Quantisation helps speed up this process, as it's faster to work with a smaller set of discrete values than a continuous range of numbers.
- Deployment on Resource-Limited Devices: LLMs are used in applications like chatbots, virtual assistants, and more. Quantisation allows these models to run smoothly on devices with limited resources, ensuring they are accessible to a broader audience.
- Fine-Tuning for Specific Tasks: Quantisation can also help fine-tune LLMs for specific tasks. By simplifying the model's parameters, you can adapt it to perform better in particular applications.
Striking a Balance
While quantisation offers numerous benefits, it's important to note that there's a trade-off between precision and resource efficiency. The more you simplify the data by reducing the number of levels, the more you save in terms of resources, but you may introduce some loss in the model's accuracy or ability to generate nuanced responses.
In conclusion, quantisation in LLMs is a clever technique that simplifies the way these models handle data. It's all about balancing the need for efficiency with maintaining the quality of responses. As LLMs continue to evolve and become a more integral part of our digital lives, understanding concepts like quantisation becomes increasingly important. It's one of the behind-the-scenes tricks that make these models so powerful and versatile.
Bionic has the flexibility for you to change up your LLM to fit in with your requirements and available infrastructure.